
Les réseaux de neurones convolutifs (CNN)
Un réseau de neurones convolutifs(ConvNet/CNN) est une méthode d'apprentissage profond qui analyse les images en leur attribuant des poids et des biais apprenables pour distinguer différents aspects ou objets. Contrairement à d'autres algorithmes de classification, les ConvNets nécessitent moins de prétraitement, car ils peuvent apprendre à reconnaître les caractéristiques pertinentes à partir des données d'entraînement, plutôt que de dépendre de filtres préalablement conçus. Ils sont conçus pour traiter efficacement des données en forme de grille, telles que les images. Ils sont composés de couches de filtres de convolution qui apprennent des représentations hiérarchiques des caractéristiques présentes dans les données d'entrée. Les CNN sont largement utilisés dans des tâches telles que la classification d'images, la détection d'objets et la segmentation d'images.
l y a 3 points clés :
-
Réduire le nombre d’entrées (équivalent pixel)
-
Absorber des petits changements dans la représentation d’objets
-
Prendre avantage de la corrélation dans les images (les pixels de mêmes couleurs sont plus probablement à côtés), de faits on ne peut pas aplatir une image directement en un vecteur d’entré, cela ferait perdre trop d’informations
Fonctionnement d’un CNN :

@Meta AI

(Source : MathWorks, https://www.mathworks.com/videos/introduction-to-deep-learning-what-are-convolutional-neural-networks--1489512765771.html)
Un CNN comprend généralement trois parties : une partie de convolution (fonction d’activation ReLu), une partie de pooling et une partie finale de réseau de neurones classique (fonction d’activation Softmax).
La convolution :
Imaginons qu’on est une image, et on veut savoir si celle-ci comprend un cercle ou non. Pour simplifier encore plus on suppose que l’image est dans une nuance d’une seule couleur.
Pour pratiquer la convolution on a :
-
Une image en entrée (grille)
-
Un kernel (qui est ajusté par rétropropagation)
-
Une nouvelle image plus petite (grille)

@Le guide en science de données
Voilà ce qu’un changement du kernel peut faire (ici que des 0 et des 1, mais ce n’est pas obligatoire du tout) :
@Le guide en science de données
Le pooling :
Le Pooling dans ce contexte correspond à l’action de résumé un ensemble de pixels un seul. Nous avons une grille et nous voulons une grille plus petite, alors on va réduire celle-ci en prenant un sous-ensemble de cette grille et la « résumer » en une seule unité de la nouvelle grille.

@Le guide en science de données
Il y a trois façons courantes de faire du pooling :
-
Max pooling (ci-dessus), où la valeur retenue est la valeur maximale
-
Average pooling, où la valeur retenue est la valeur moyenne
-
Sum pooling, où la valeur retenue est la somme
Contrairement au processus de convolution, les grilles ne se chevauchent pas.
Dans notre exemple d’identification de cercle le max pooling à la meilleure performance.
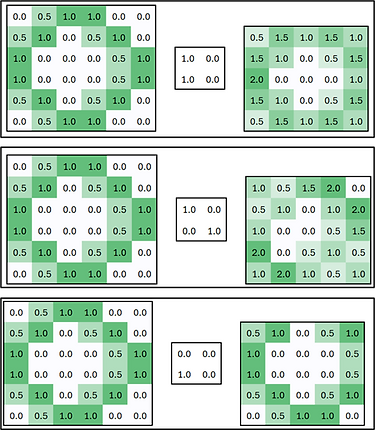
Les deux autres méthodes sont montrées ci-dessous :

@Le guide en science de données
Processus complet :

@Le guide en science de données
On peut supposer que notre réseau de neurone a appris que lorsque l’unité centrale (5ème valeur) vos 1 et lorsque les autres valent 2 ou plus, on est en présence d’un cercle.
Selon le postulat fait sur l’apprentissage de notre réseau, on peut voir que cela généralise plus ou moins bien.

@Le guide en science de données

@Le guide en science de données
Dans le monde réel chaque pixel se résume comme un indice RGB, donc la profondeur de chaque grille est de 3, il en va de même pour le kernel. Les images comprennent beaucoup plus de pixel que dans notre exemple d’où la nécessité de réduire cette taille, mais il faut aussi réduire le détail pour identifier des patterns qui nous permettrons de faire de la classification. On voit bien dans notre exemple que le pattern est bien identifié dans les 2 premier cas (pas dans le 3ème).